
If you’re here, more likely than not, you know how messy data integration can be. It’s like trying to organize a room with lots of stuff all over the place – you know where the stuff should go, but walking around the mess without tripping is another story. Let’s say that you’ve got data in various databases, data models, and locations, and now you need to integrate them into one coherent and usable format. Sounds daunting, doesn’t it? Data integration patterns are where you should start.
However, there must be an ideal manner of transfer of data in order to avoid the costly woes related to transition disruptions. In this blog, we will highlight 5 data integration patterns that will help you navigate the data integration process smoothly, overcoming the pitfalls and offering pragmatic tools to save you time.
What is Data Integration?
Data integration refers to the process of bringing together data from different sources in order to have one unified view. Through this, a system or an application will have the ability to exchange data with other systems or applications that are dissimilar. This process seeks to reconcile, transform and condense data that is useful in analysis, reporting and decision-making.
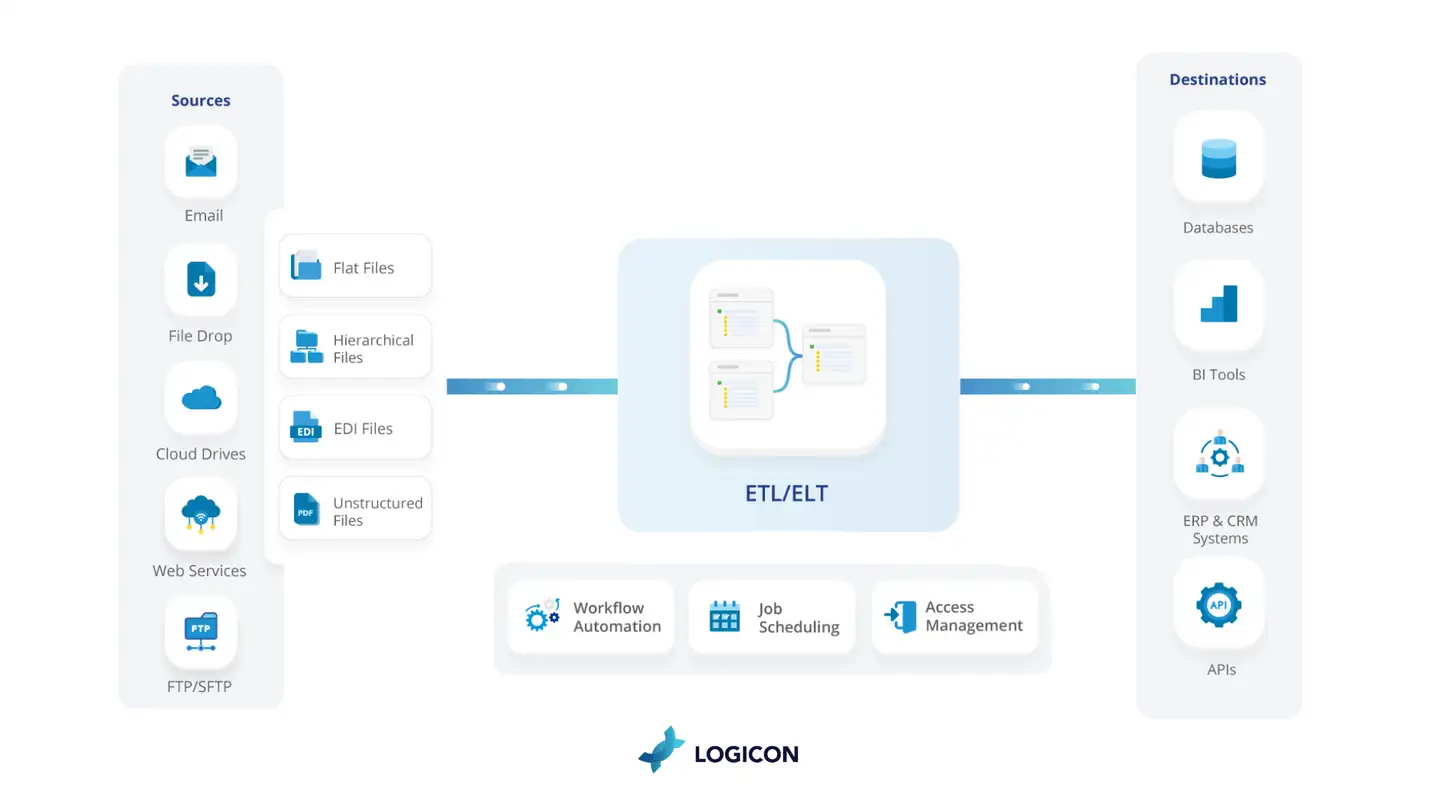
Key Components of Data Integration:
- Data Extraction: Extraction of data from databases, files, APIs, streaming platforms and so on.
- Data Transformation: Normalization, cleaning, augmentation, and aggregation of the data.
- Data Loading: Loading transformed data into a centralized repository or into a target system, and ensuring data integrity and consistency.
- Data Synchronization: Guaranteeing that the data is being tracked up-to-date and synchronized across the distributed systems or databases.
Benefits of Data Integration:
- Improved Data Quality: Through consolidating data from different places, data integration assures data integrity, uniformity, and completeness.
- Enhanced Decision-Making: A consolidating vision of data enables powerful analysis, reporting and decision making across departments or business units.
- Increased Operational Efficiency: Simplifying data exchange and integration procedures lowers manual workload and boosts productivity.
- Facilitated Business Intelligence: The data integration provides for creating strategic planning and forecasting.
- Adaptability and Scalability: Scalable data integration solutions are capable of handling growing data volumes and are flexible to changing business requirements.
Challenges of Data Integration:
- Data Quality: The importance of data validation, uniformity, and completeness of data from different sources can be difficult to accomplish.
- Data Security: The protection of sensitive information and the observance of privacy regulations are vital.
- Complexity: Managing and taking care of complicated integration architectures and workflows need technical knowledge and resources.
- Legacy Systems: Combining data from legacy systems or technological platforms with the latest technologies can be complex and time-consuming.
- Data Governance: It is necessary to define clear data governance policies and protocols for successful data integration.
5 data integration patterns
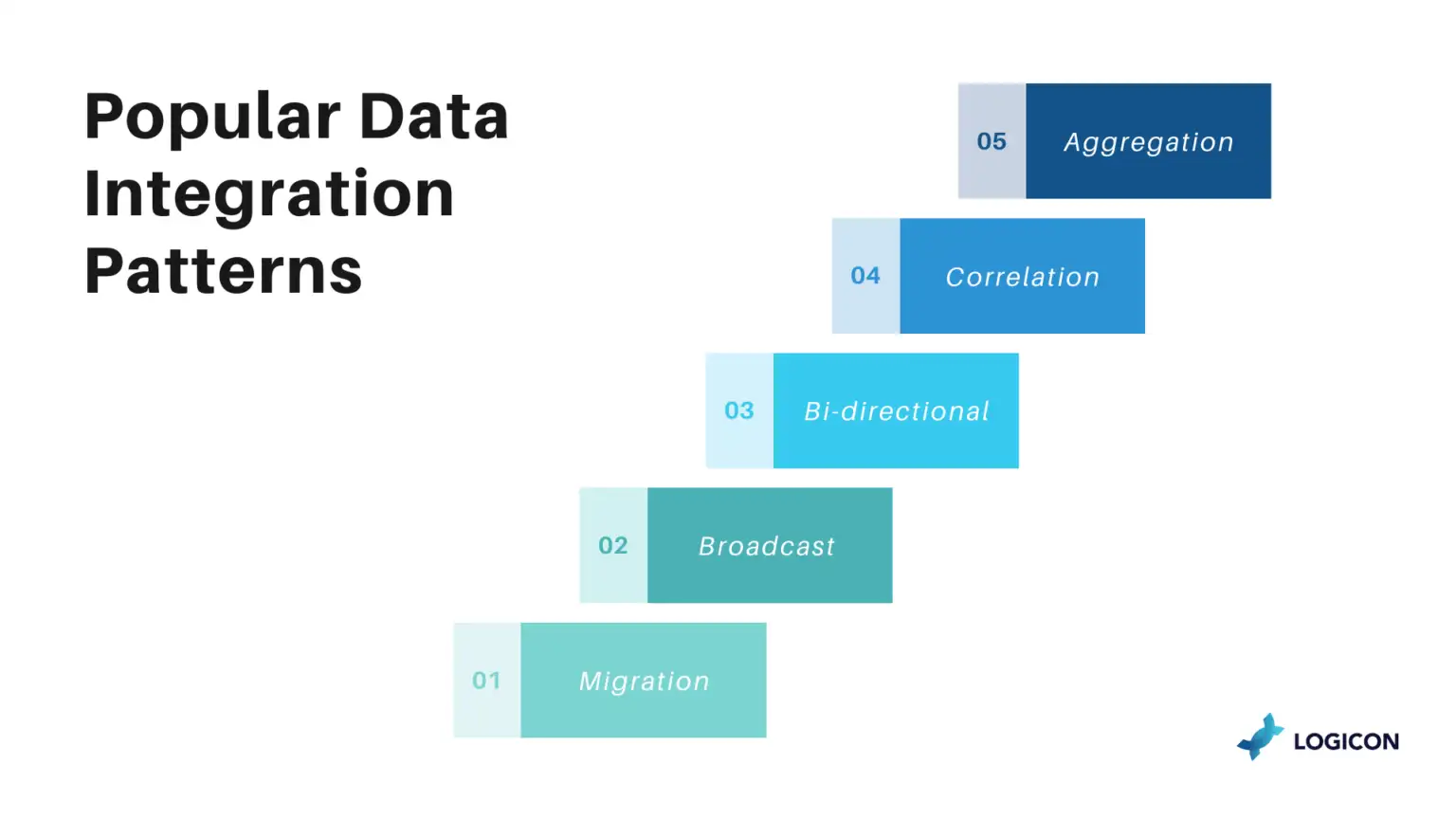
Data Migration Pattern
Data Migration Pattern is the process of transferring data from one system or storage format to another one. It is during system upgrades, migrations to new platforms, or merging data from various sources into a single repository. This approach enables data transfer with zero loss of quality and uninterrupted consistency.
Characteristics and Key Features:
- Seamless transfer of data from source to destination.
- Transformation and mapping of data to fit the target system’s schema.
- Incremental migration to minimize downtime and disruptions.
- Data validation and verification to ensure accuracy and completeness.
Use Cases and Scenarios:
- Migrating data from on-premises servers to cloud-based platforms.
- Upgrading legacy systems to modern applications.
- Consolidating data from multiple departments or subsidiaries into a central data warehouse.
Advantages:
- Facilitates the adoption of new technologies and platforms.
- Minimizes disruptions to business operations.
- Enables data consolidation for improved analysis and reporting.
- Supports compliance with data privacy regulations.
Disadvantages:
- Risk of data loss or corruption if migration process is not properly executed.
- Potential for downtime during migration, impacting business continuity.
- Complexity in handling large volumes of data or heterogeneous sources.
- Requires careful planning and coordination across departments and stakeholders.
The Broadcast Pattern
The Broadcast Pattern involves distributing data from a single source to multiple destinations or consumers simultaneously. It serves as a broadcasting mechanism where data is sent out once and received by multiple subscribers, ensuring that all recipients have access to the same information in real-time.
Characteristics and Key Features:
- One-to-many communication model where a single message is broadcasted to multiple recipients.
- Asynchronous communication to enable decoupling between producers and consumers.
- Scalability to accommodate varying numbers of subscribers without impacting performance.
- Support for various messaging protocols such as publish-subscribe or event-driven architectures.
Use Cases and Scenarios:
- Broadcasting real-time market data to multiple trading platforms in financial institutions.
- Distributing updates or notifications to subscribers in a messaging system.
- Propagating changes to distributed databases or caches in a microservices architecture.
Advantages:
- Real-time dissemination of information to multiple recipients.
- Reduced network traffic and resource utilization compared to point-to-point communication.
- Decoupling of producers and consumers, allowing for flexible scalability and system evolution.
- Support for fault tolerance and reliability through redundancy and failover mechanisms.
Disadvantages:
- Complexity in managing message delivery and ensuring consistency across multiple subscribers.
- Potential for message overload or contention in highly distributed systems.
- Difficulty in maintaining ordering guarantees across multiple recipients.
- Increased risk of security vulnerabilities if not properly secured against unauthorized access.
Bi-directional Pattern
The Bi-directional Pattern facilitates bi-directional data flow between two or more systems, allowing for communication and synchronization of data changes in both directions. This pattern enables systems to exchange information and keep data consistent across distributed environments.
Characteristics and Key Features:
- Two-way communication between systems, allows data updates in both directions.
- Conflict resolution mechanisms to handle conflicting changes made to the same data.
- Synchronization protocols to ensure consistency between distributed copies of data.
- Support for real-time or near-real-time data replication and propagation.
Use Cases and Scenarios:
- Synchronizing customer data between CRM (Customer Relationship Management) and ERP (Enterprise Resource Planning) systems.
- Integrating inventory levels between warehouse management and e-commerce platforms.
- Replicating data between on-premises databases and cloud-based applications for disaster recovery or data migration.
Advantages:
- Enables real-time synchronization of data between systems, reducing data discrepancies and inconsistencies.
- Facilitates seamless collaboration and data sharing between distributed teams or departments.
- Supports offline operation by allowing changes to be made locally and synchronized when connectivity is restored.
- Enhances data availability and reliability by maintaining redundant copies across multiple systems.
Disadvantages:
- Complexity in handling conflict resolution and ensuring data consistency in distributed environments.
- Potential for data conflicts or inconsistencies if synchronization mechanisms are not properly implemented.
- Increased network bandwidth and resource utilization due to bidirectional data transfer.
- Dependency on robust error handling and recovery mechanisms to mitigate data synchronization failures.
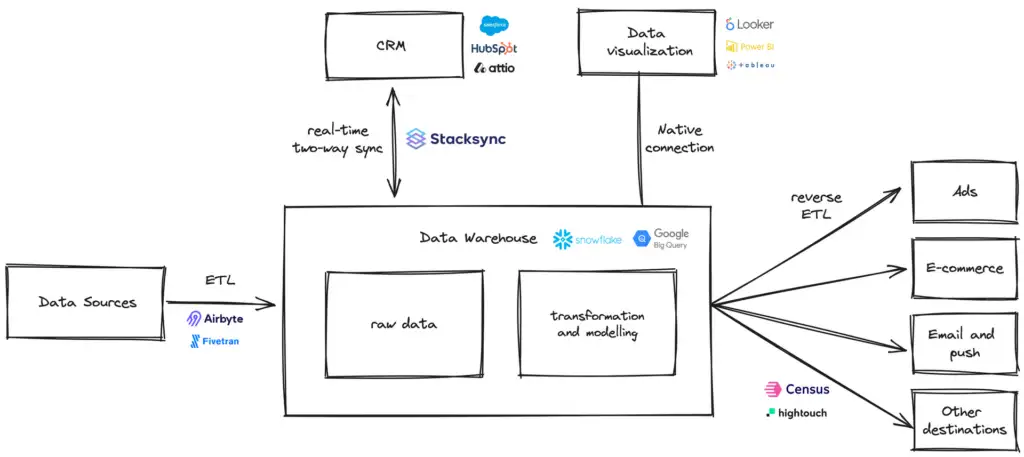
Correlation Pattern
The Correlation Pattern involves identifying and linking related data elements across different sources or systems based on common attributes or relationships. This pattern aims to establish meaningful connections between disparate data sets to derive insights or enable further analysis.
Characteristics and Key Features:
- Identification of correlation criteria or key attributes to establish relationships between data elements.
- Matching and linking of correlated data based on predefined rules or algorithms.
- Support for both automated correlation techniques and manual intervention for complex scenarios.
- Integration with data quality tools to ensure accuracy and reliability of correlation results.
Use Cases and Scenarios:
- Linking customer records from different systems based on common identifiers such as email addresses or account numbers.
- Correlating sensor data from IoT devices with geographical location information for spatial analysis.
- Identifying connections between social media profiles to uncover patterns or relationships in social networks.
Advantages:
- Enables the discovery of hidden relationships or patterns within large and diverse data sets.
- Facilitates data enrichment by combining information from multiple sources to enhance analysis.
- Supports contextual insights by correlating data across different dimensions or perspectives.
- Improves data accuracy and completeness by resolving redundancies and inconsistencies.
Disadvantages:
- Complexity in defining correlation criteria and rules that accurately capture meaningful relationships.
- Challenges in handling noisy or incomplete data that may impact correlation accuracy.
- Potential for false positives or misleading correlations if not properly validated or verified.
- Performance implications in processing large volumes of data or complex correlation algorithms.
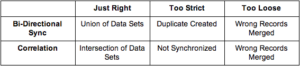
Aggregation Pattern
The Aggregation Pattern involves combining and summarizing data from multiple sources into a single unified view or dataset. This pattern allows organizations to aggregate, consolidate, and analyze data from disparate sources to derive insights and make informed decisions.
Characteristics and Key Features:
- Collection of data from diverse sources, such as databases, files, APIs, or streaming sources.
- Aggregation functions are applied to combine data, including sum, average, count, min, and max.
- Grouping of data based on common attributes or dimensions for summarization.
- Transformation of raw data into meaningful aggregates for reporting, analysis, or visualization.
Use Cases and Scenarios:
- Aggregating sales data from different regions to calculate total revenue and performance metrics.
- Summarizing customer feedback from multiple channels to identify trends and sentiment analysis.
- Combining sensor data from IoT devices to monitor and optimize industrial processes.
Advantages:
- Provides a consolidated view of data for decision-making and analysis.
- Reduces complexity by centralizing data aggregation and processing.
- Enhances scalability by handling large volumes of data efficiently.
- Enables the creation of customized reports and dashboards for stakeholders.
Disadvantages:
- Loss of granularity or detail in aggregated data compared to raw source data.
- Complexity in defining aggregation logic and handling data outliers or anomalies.
- Potential performance bottlenecks when aggregating large datasets in real-time.
- Requires careful consideration of data quality and consistency across aggregated sources.
FAQs: Data Integration Patterns
Is API gateway a pattern?
Yes, API Gateway is included as one of the data integration patterns. It is the primary location for handling and routing data among different systems, applications, and services. The standardization and unification of API interactions means data flows across heterogeneous environments easily and seamlessly.
What is data migration vs data integration?
Data migration refers to the process of moving data from one system or platform to another, which is often associated with system upgrades, replacements or consolidations. The goal is to provide reliable data transfer without compromising its validity and wholeness.
However, data integration is a broader concept including, the integration process of data coming from different sources or formats to provide a single view. It entails integrating, transforming and consolidating data from different sources which allows for analysis, reporting and decision making. Contrary to data migration which is a single event, data integration is an ongoing process designed to keep data synchronicity and coherence across the organization.
What are enterprise integration patterns?
Enterprise Integration Patterns (EIPs) refer to a set of standard patterns describing the common challenges faced in integrating various systems within an overall enterprise architecture framework. These patterns present the standard solution to sophisticated integration issues, namely: message routing, data transformation and protocol translation.
EIPs are a roadmap to developing reliable, scalable, and maintainable integration architectures by providing templates and proven techniques that can be utilized for future integration solutions. Instances of EIPs are Message Channel, Message Router, Content-Based Router, and Message Translator. By bringing these patterns into play, businesses can speed up their integration, improve intercommunicating systems, and become more flexible in responding to business needs.
How do you create integration?
Integration design begins by pinpointing the data or processes in need of connecting. Next, choose applicable tools and technologies for instance APIs or integration platforms. Build the integration architecture, create the appropriate logic and thoroughly test it for proper functioning. When the integration is tested, move it to production, monitor its performance, and maintain it frequently to ensure its continued functionality and optimization.
What is an example of data integration?
An instance of data integration is a retailer collecting data from different sources such as sales transactions, customer interactions and warehouse inventory into a unified data warehouse. The company is able to integrate this information and therefore can get insights into customer behavior, optimize inventory management, as well as improve the decision-making process across the sales machine, marketing and supply chain management departments.

Wrapping Up: Data Integration Patterns
As we wrap up our exploration of data integration patterns, here’s a bonus tip: Give priority to data quality before, during, and after data migration. Invest in data cleansing and validation processes, which guarantee the accuracy and consistency of the data, thus minimizing the risks of errors. Keep in mind that accurate data is the key to effective analysis and decision-making.
Through Logicon data integration services, your data integration will be moved to the next level if you are ready to do so. With our team of experts, you will be able to tackle the challenges of data migration and enhance your data management procedures. We are here for you on a one-on-one basis and will customize solutions to fit your specific requirements.